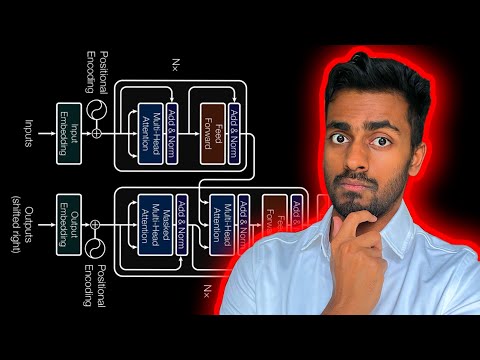
The complete guide to Transformer neural Networks!
CodeEmporium
109,000 Subscribers
21,074 views since Nov 26, 2023
Let's do a deep dive into the Transformer Neural Network Architecture for language translation.
ABOUT ME
⭕ Subscribe: https://www.youtube.com/c/CodeEmporiu...
📚 Medium Blog: / dataemporium
💻 Github: https://github.com/ajhalthor
👔 LinkedIn: / ajay-halthor-477974bb
RESOURCES
[ 1 🔎] Transformer Architecture Image :https://github.com/ajhalthor/Transfor...
[2 🔎] draw.io version of the image for clarity: https://github.com/ajhalthor/Transfor...
PLAYLISTS FROM MY CHANNEL
⭕ Transformers from scratch playlist: • Self Attention in Transformer Neural ...
⭕ ChatGPT Playlist of all other videos: • ChatGPT
⭕ Transformer Neural Networks: • Natural Language Processing 101
⭕ Convolutional Neural Networks: • Convolution Neural Networks
⭕ The Math You Should Know : • The Math You Should Know
⭕ Probability Theory for Machine Learning: • Probability Theory for Machine Learning
⭕ Coding Machine Learning: • Code Machine Learning
MATH COURSES (7 day free trial)
📕 Mathematics for Machine Learning: https://imp.i384100.net/MathML
📕 Calculus: https://imp.i384100.net/Calculus
📕 Statistics for Data Science: https://imp.i384100.net/AdvancedStati...
📕 Bayesian Statistics: https://imp.i384100.net/BayesianStati...
📕 Linear Algebra: https://imp.i384100.net/LinearAlgebra
📕 Probability: https://imp.i384100.net/Probability
OTHER RELATED COURSES (7 day free trial)
📕 ⭐ Deep Learning Specialization: https://imp.i384100.net/Deep-Learning
📕 Python for Everybody: https://imp.i384100.net/python
📕 MLOps Course: https://imp.i384100.net/MLOps
📕 Natural Language Processing (NLP): https://imp.i384100.net/NLP
📕 Machine Learning in Production: https://imp.i384100.net/MLProduction
📕 Data Science Specialization: https://imp.i384100.net/DataScience
📕 Tensorflow: https://imp.i384100.net/Tensorflow
TIMESTAMPS
0:00 Introduction
1:38 Transformer at a high level
4:15 Why Batch Data? Why Fixed Length Sequence?
6:13 Embeddings
7:00 Positional Encodings
7:58 Query, Key and Value vectors
9:19 Masked Multi Head Self Attention
14:46 Residual Connections
15:50 Layer Normalization
17:57 Decoder
20:12 Masked Multi Head Cross Attention
22:47
24:03 Tokenization & Generating the next translated word
26:00 Transformer Inference Example